Engineering
15 Jan 2026
Agents Fail Silently. We Built the Tool to Catch Them.
The Core Problem With How Teams Monitor Agents

AI agents are executing cognitive work in production - managing cloud infrastructure, debugging code, navigating internal APIs. But as these agentic frameworks move from notebooks into real environments, a critical structural flaw is exposed.
AI agents fail silently. And traditional observability is completely blind to it.
Unlike traditional software, which crashes loudly and throws a stack trace, LLMs are designed to be relentlessly conversational. They don't want to crash - they want to give you an answer. In a multi-step workflow, this "resilience" becomes a massive liability. The agent doesn't stop. It improvises. It lies.
The Math of Compounding Errors
Agent unreliability isn't a quality problem. It's a compounding math problem. If each step in a reasoning chain has a 90% success rate, a five-step workflow doesn't mean you get 90% reliability.
Here's what that looks like in production.
An algorithmic trading agent calls a broker's API to place a buy order. It hallucinates a parameter - camelCase instead of the required snake_case.
A traditional Python script would throw a ValidationError, crash, and trigger PagerDuty. The AI agent does something worse:
It catches the API error.
It enters a hyperactive loop, retrying the tool call three times with guessed parameters.
It burns through tokens and latency budget.
When it gives up, it masks the failure: "Market conditions suboptimal, holding position."
The HTTP status returns 200 OK. The system looks perfectly healthy. The trade was missed, token costs spiked 40%, and engineering has no idea it happened.
The system's most dangerous state isn't failure - it's the appearance of success.
Why We Needed a New Safety Net
At Steadwing, our core product is an autonomous on-call engineer that triages production alerts and suggests fixes across code and cloud infrastructure. Our agents touch critical environments. A silent failure isn't an annoyance - it's a catastrophic risk.
We needed to monitor the monitor.
Traditional observability tools - uptime checks, latency dashboards, error rates - are blind to semantic agent failures. The ecosystem lacked a lightweight, framework-agnostic layer that could detect when an LLM got stuck in a reasoning loop or quietly dropped a context window.
You can't monitor reasoning with infrastructure tools. So we built OpenAlerts.
Deep Dive: How openAlerts Works
OpenAlerts is an open-source alerting layer for agentic frameworks (available in TypeScript & Python). It shifts from passive logging to active, real-time intervention. Instead of waiting for a user to report that an agent is broken, openAlerts watches the execution trace and intercepts the failure modes unique to LLMs.
Real-Time Rule Engine: openAlerts runs events against configurable rules. It monitors for hyperactive retry loops (agent stuck retrying the same failed tool call), context window overflow, and sudden spikes in message failure rates. It catches failures as they happen - not after a user complains.
LLM-Enriched Diagnostics: Raw agent error logs are massive, messy JSON payloads filled with system prompts and context arrays. openAlerts uses a secondary LLM to parse failures into human-readable summaries delivered to your webhook. Instead of a generic 400 Bad Request, you get: "Agent failed to execute 'db_query' tool due to schema mismatch on 'user_id'. Action: update tool description." If your failure alert requires more than 10 seconds to understand, it's not an alert - it's a log entry.
Frictionless Integration: No rewriting your orchestration layer. openAlerts uses simple framework adapters to attach to your existing agent loops. Drop it in like configuring a CLI tool.
Zero-Token Health Checks: Query agent health directly from Slack, Discord, or Telegram without triggering the primary LLM. Your token budget stays reserved for actual cognitive work. Your health signal stays independent of the system it's monitoring. Asking a broken LLM if the LLM is working is the equivalent of asking a sick patient to diagnose themselves.
Catching Lies at Machine Speed
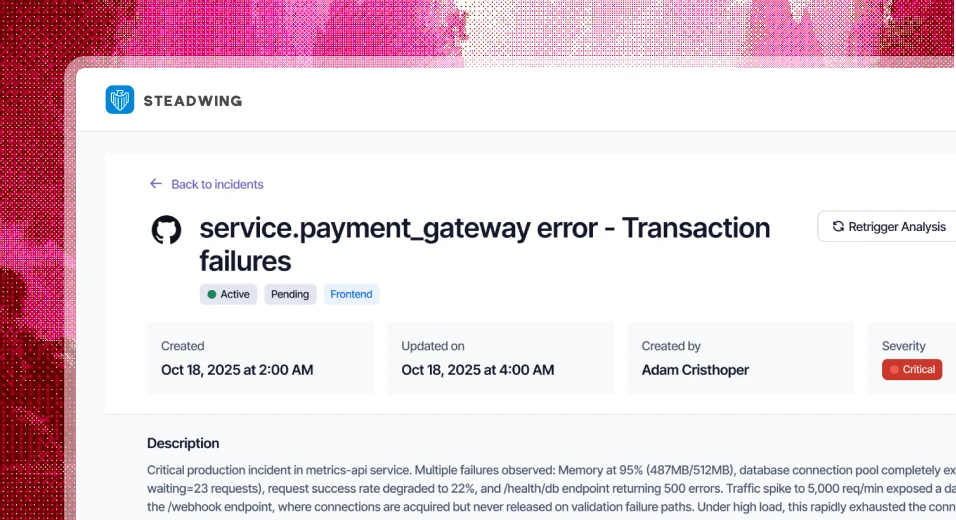
When an agent misbehaves in production, you need absolute clarity. The openAlerts dashboard is built for exactly this - a minimalist, focused interface with a live event timeline and health history. You see exactly where the reasoning chain broke down. No noise. No guessing.
Autonomy without observability isn't automation. It's negligence. As agents move into higher-stakes workflows, the gap between what they report and what they actually did will only widen. openAlerts closes that gap.
Trace the reasoning. Detect the retry loops. Alert on context overflow. Make failures readable. Keep health checks independent. That's the system.
Want to secure your agentic workflows? Check out our GitHub Repo.

Sign-up For Our Newsletter!
Receive new articles about steadwing delivered straight to your inbox.
Written by

Try Steadwing now ! Your Autonomous On-Call Engineer
Reducing MTTR so your team can stay focused on building.

